

 David, Kyle and Alex just published their SHAPE-Seq 2.0 paper in Nucleic Acids Research. This paper was a monumental amount of work, and aimed to address two big issues in the SHAPE-Seq experiment – examining whether or not there were biases in the experiment due to the various steps of the next-generation sequencing aspect of the experiment, and making the experiment more accessible. To tackle the first issue, David started out by performing SHAPE-Seq v1.0 experiments on a panel of RNAs that the field has started to use to benchmark chemical probing experiments. To investigate whether or not SHAPE-Seq gave systematically different reactivities than SHAPE analyzed by capillary electrophoresis (SHAPE-CE), David performed experiments on this panel using QuSHAPE and compared the two data sets. We noticed that the two gave qualitatively similar results, but did differ in the quantitative reactivities measured. To investigate further, David and Kyle performed many experiments and optimizations to test whether the adapter ligation conditions or PCR cycles affected reactivities. Through many comparisons, we did not find any systematic biases. As a bonus, we ended up with a highly optimized version of the SHAPE-Seq experiment.
David, Kyle and Alex just published their SHAPE-Seq 2.0 paper in Nucleic Acids Research. This paper was a monumental amount of work, and aimed to address two big issues in the SHAPE-Seq experiment – examining whether or not there were biases in the experiment due to the various steps of the next-generation sequencing aspect of the experiment, and making the experiment more accessible. To tackle the first issue, David started out by performing SHAPE-Seq v1.0 experiments on a panel of RNAs that the field has started to use to benchmark chemical probing experiments. To investigate whether or not SHAPE-Seq gave systematically different reactivities than SHAPE analyzed by capillary electrophoresis (SHAPE-CE), David performed experiments on this panel using QuSHAPE and compared the two data sets. We noticed that the two gave qualitatively similar results, but did differ in the quantitative reactivities measured. To investigate further, David and Kyle performed many experiments and optimizations to test whether the adapter ligation conditions or PCR cycles affected reactivities. Through many comparisons, we did not find any systematic biases. As a bonus, we ended up with a highly optimized version of the SHAPE-Seq experiment.
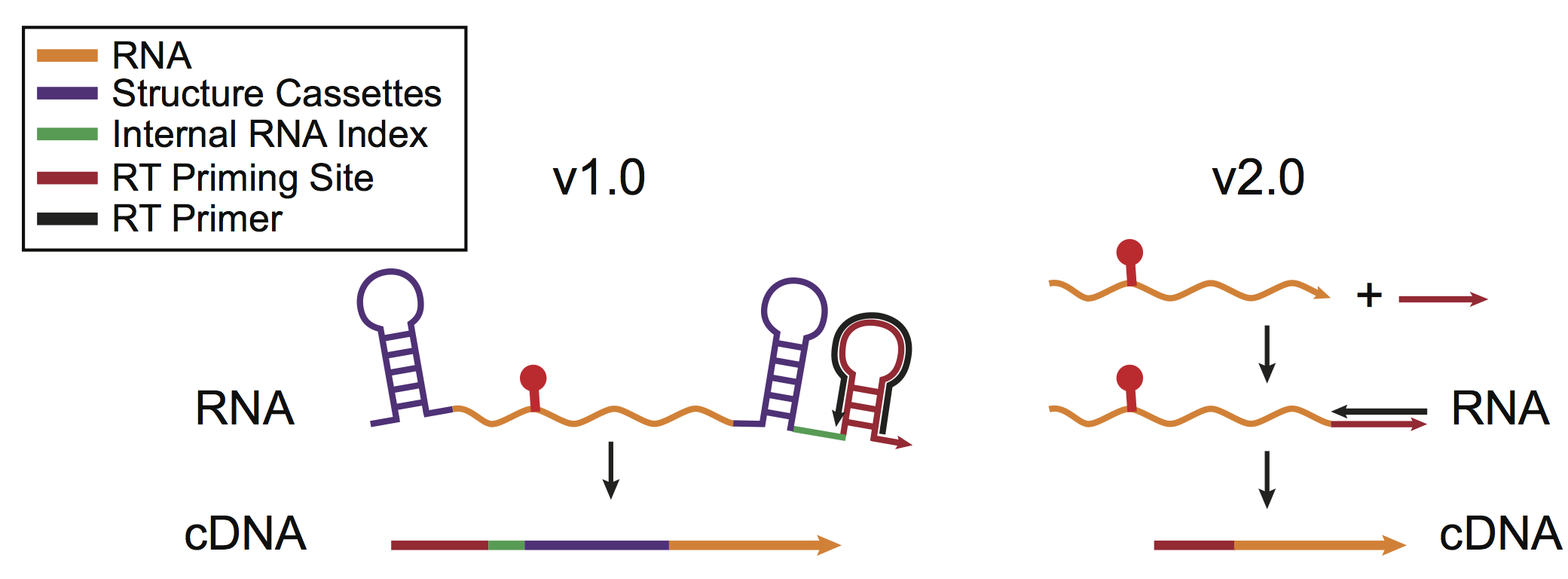
Next, Kyle, with the help of Alex, worked on making the SHAPE-Seq experiment much more accessible. To do so they created a new linker ligation strategy to allow the probing step to be performed on RNAs without having to use an internal RT priming site, or introduce one by adding flanking sequence (as is typically done with in vitro SHAPE-like experiments). In this new technique called SHAPE-Seq 2.0, the RNA is modified, then a linker is ligated which serves as a landing site for the reverse transcriptase primer. SHAPE-Seq 2.0 ends up being a more ‘universal’ experiment since the same thing is done no matter what the RNA being studied – whether it is transcribed and folded in vitro or it comes from a natural source.
Finally the team assessed whether or not SHAPE-Seq data could be used to increase the accuracy of RNA structural predictions. To do this we performed replicate SHAPE-Seq experiments (to also asses the reproduceability of the technique), and in fact found that SHAPE-Seq data give the same improvements in structure prediction as any of the other published SHAPE-based methods.
This is a big paper for the lab since it not only represents a lot of great optimizations and extensions of SHAPE-Seq, but it is also our first SHAPE-Seq paper! In the process, we also updated the spats data analysis pipeline, and we also released all the data in the paper through the RNA Mapping Database (RMDB) so that anyone can download and analyze this data.
Congratulations team!
Link to the paper: http://dx.doi.org/10.1093/nar/gku909
Link to spats v0.8.0: http://spats.sourceforge.net
Link to the data in the RMDB: http://rmdb.stanford.edu/repository/search?searchtext=10.1093%2Fnar%2Fgku909
